TensorOpera AI Wprowadza Fox-1: Serię Małych Modeli Językowych (SLM), w Tym Fox-1-1.6B i Fox-1-1.6B-Instruct-v0.1
W ostatnich latach rozwój modeli językowych o dużej liczbie parametrów (LLM) znacząco wpłynął na szeroki zakres zastosowań, od rozwiązywania problemów matematycznych po odpowiadanie na pytania medyczne. Jednakże, ze względu na ich olbrzymi rozmiar i zasoby obliczeniowe potrzebne do trenowania i wdrażania, stają się one coraz mniej praktyczne. Modele te, jak te opracowane przez OpenAI czy Google, często zawierają setki miliardów parametrów, co wymaga ogromnych zbiorów danych oraz wysokich kosztów treningu. To z kolei prowadzi do obciążeń finansowych i ekologicznych, które sprawiają, że te modele są niedostępne dla wielu badaczy i organizacji. Zwiększająca się skala modeli rodzi również obawy dotyczące wydajności, opóźnień i możliwości ich efektywnego wdrożenia w rzeczywistych zastosowaniach, gdzie zasoby obliczeniowe mogą być ograniczone.
TensorOpera AI wprowadza Fox-1: Seria Małych Modeli Językowych (SLM)
W odpowiedzi na te wyzwania, TensorOpera AI wypuściło serię Fox-1, która oferuje Małe Modele Językowe (SLM), mające na celu dostarczenie możliwości porównywalnych z LLM przy znacznie mniejszych wymaganiach dotyczących zasobów. Fox-1 obejmuje głównie dwa warianty: Fox-1-1.6B oraz Fox-1-1.6B-Instruct-v0.1, które zostały zaprojektowane, aby zapewnić solidne możliwości przetwarzania języka, pozostając jednocześnie niezwykle efektywnymi i dostępnymi. Modele te przeszły trening na bazie 3 bilionów tokenów danych pobranych z internetu oraz zostały dostrojone przy użyciu 5 miliardów tokenów do zadań związanych z przestrzeganiem instrukcji i rozmowami wielokrotnymi. Dzięki udostępnieniu tych modeli na licencji Apache 2.0, TensorOpera AI dąży do promowania otwartego dostępu do potężnych modeli językowych i demokratyzacji rozwoju sztucznej inteligencji.
Szczegóły techniczne
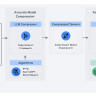
Fox-1 wyróżnia się na tle innych modeli SLM dzięki kilku innowacjom technicznym. Jedną z nich jest trzystopniowy program nauczania danych, który zapewnia stopniową progresję w treningu, przechodząc od ogólnego kontekstu do wysoce specjalistycznego. Podczas treningu dane zostały zorganizowane w trzy odrębne etapy, wykorzystując długości sekwencji od 2K do 8K, co pozwala Fox-1 efektywnie uczyć się zarówno krótkich, jak i długich zależności w tekście. Architektura modelu to głębszy wariant transformera dekodera, składający się z 32 warstw, co jest znacząco głębsze w porównaniu do konkurencyjnych modeli, takich jak Gemma-2B czy StableLM-2-1.6B.
Oprócz głębszej architektury, Fox-1 wykorzystuje mechanizm Grouped Query Attention (GQA), który optymalizuje wykorzystanie pamięci i poprawia szybkość zarówno trenowania, jak i wnioskowania. Zwiększony rozmiar słownika do 256 000 tokenów dodatkowo poprawia zdolność modelu do rozumienia i generowania tekstu z mniejszą dwuznacznością tokenizacji. Dzięki współdzieleniu osadzania wejściowego i wyjściowego, Fox-1 redukuje łączną liczbę parametrów, co skutkuje bardziej zwartym i efektywnym modelem. Te innowacje pozwalają Fox-1 osiągnąć najwyższą jakość w zadaniach językowych bez obciążeń obliczeniowych, które zazwyczaj towarzyszą dużym modelom językowym.
Wyniki wydajności
Wydanie Fox-1 ma szczególne znaczenie z kilku powodów. Po pierwsze, model rozwiązuje kluczowy problem dostępności sztucznej inteligencji. Dzięki dostarczeniu modelu, który jest zarówno wydajny, jak i zdolny, TensorOpera AI udostępnia zaawansowane rozumienie i generowanie języka szerszemu gronu odbiorców, w tym badaczom i deweloperom, którzy mogą nie mieć dostępu do infrastruktury obliczeniowej potrzebnej do trenowania większych LLM. Fox-1 został porównany z wiodącymi modelami SLM, takimi jak StableLM-2-1.6B, Gemma-2B i Qwen1.5-1.8B, i konsekwentnie osiągał równie dobre lub lepsze wyniki w różnych standardowych testach, takich jak ARC Challenge, MMLU i GSM8k.
Pod względem konkretnych wyników, Fox-1 osiągnął 36,39% dokładności w teście GSM8k, przewyższając wszystkie porównywane modele, w tym Gemma-2B, który jest dwukrotnie większy. Model ten wykazał również lepszą wydajność w teście MMLU, mimo mniejszych rozmiarów. Efektywność wnioskowania Fox-1 została zmierzona za pomocą vLLM na procesorach NVIDIA H100, gdzie osiągnął on ponad 200 tokenów na sekundę, dorównując przepustowością większym modelom, takim jak Qwen1.5-1.8B, przy jednoczesnym mniejszym zużyciu pamięci GPU. Ta wydajność sprawia, że Fox-1 jest atrakcyjnym wyborem dla aplikacji wymagających wysokiej wydajności, ale ograniczonych przez dostępne zasoby sprzętowe.
Podsumowanie
Seria Fox-1 od TensorOpera AI to znaczący krok naprzód w rozwoju małych, ale potężnych modeli językowych. Dzięki połączeniu wydajnej architektury, zaawansowanych mechanizmów uwagi oraz przemyślanej strategii treningowej, Fox-1 oferuje imponującą wydajność porównywalną z dużo większymi modelami. Dzięki open-source’owemu wydaniu, Fox-1 ma szansę stać się cennym narzędziem dla badaczy, deweloperów i organizacji, które chcą wykorzystać zaawansowane możliwości językowe bez ponoszenia wysokich kosztów związanych z dużymi modelami językowymi. Modele Fox-1-1.6B i Fox-1-1.6B-Instruct-v0.1 dowodzą, że możliwe jest osiągnięcie wysokiej jakości rozumienia i generowania języka przy bardziej efektywnym i zoptymalizowanym podejściu.