„Praktyczne podejście do wyboru danych: Jak usprawnić i ulepszyć proces fine-tuningu”
W świecie uczenia maszynowego kluczowym wyzwaniem stało się dostosowywanie dużych modeli bazowych, takich jak BERT czy LLAMA, do specyficznych zadań. Proces ten, zwany fine-tuningiem, pozwala osiągać znakomite wyniki w wielu dziedzinach, ale jego sukces zależy nie tylko od modelu, lecz także od jakości i trafności danych treningowych. W dobie ogromnych repozytoriów, takich jak Common Crawl, które zawierają miliardy dokumentów, ręczne wybieranie odpowiednich danych jest praktycznie niemożliwe. Dlatego kluczowym elementem staje się automatyzacja selekcji danych. Niestety, obecne metody często nie spełniają trzech głównych wymagań: dostosowania do rozkładu danych dla zadania, zachowania różnorodności danych oraz efektywności przy pracy z ogromnymi zbiorami. W tym kontekście nowe podejście – Task-Specific Data Selection (TSDS) – wprowadza nową jakość w procesie selekcji danych.
Wprowadzenie TSDS: Optymalizacja selekcji danych
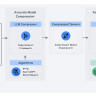
Zespół badaczy z Uniwersytetu Wisconsin-Madison, Uniwersytetu Yale oraz Apple opracował nowatorskie rozwiązanie – TSDS (Task-Specific Data Selection). Jest to framework oparty na sztucznej inteligencji, którego celem jest inteligentny dobór danych, aby poprawić skuteczność modeli w określonych zadaniach. TSDS korzysta z niewielkiej, reprezentatywnej próbki danych z docelowego zadania, aby automatycznie i skalowalnie optymalizować proces selekcji. Kluczowym elementem tej metody jest podejście oparte na problemie optymalizacyjnym, które skupia się na dopasowaniu rozkładu wybranych danych do rozkładu docelowego zadania, przy jednoczesnym zachowaniu różnorodności danych. Dzięki temu modele mogą lepiej uczyć się na danych, które odzwierciedlają realne przypadki użycia, co prowadzi do wyższej efektywności w realizacji konkretnych zadań.
TSDS opiera się na teorii transportu optymalnego, aby minimalizować różnice między rozkładem wybranych danych a rozkładem danych dla zadania. Dodatkowo framework wykorzystuje mechanizmy regulacyjne, które zwiększają różnorodność i zapobiegają nadmiernemu dopasowaniu, co mogłoby się wydarzyć w przypadku dominacji zduplikowanych przykładów w zbiorze treningowym. Dzięki zastosowaniu estymacji gęstości jądrowej TSDS skutecznie ogranicza ryzyko nadmiernego dopasowania, jednocześnie zapewniając skalowalność poprzez wykorzystanie algorytmów wyszukiwania najbliższych sąsiadów.
Techniczne aspekty i korzyści TSDS
TSDS stawia na równowagę między dwoma celami: dopasowaniem rozkładu danych a różnorodnością. Dopasowanie rozkładu realizowane jest poprzez funkcję kosztu opartą na teorii transportu optymalnego, co zapewnia, że wybrane dane są jak najbardziej zbliżone do danych dla zadania docelowego. Z kolei różnorodność danych jest zachowywana dzięki zastosowaniu mechanizmu regulacyjnego, który karze nadmiarowe powielanie zduplikowanych przykładów. Framework wykorzystuje estymację gęstości jądrowej, aby mierzyć poziom duplikacji w zbiorze danych i odpowiednio dostosowywać proces selekcji.
Proces selekcji danych w TSDS sprowadza się do określenia prawdopodobieństwa wyboru punktów danych z ogromnej puli kandydatów, faworyzując te, które najlepiej pasują do rozkładu zadania docelowego. Dzięki temu można efektywnie wykorzystać jedynie niewielką część dostępnych danych, co znacząco redukuje zapotrzebowanie na zasoby obliczeniowe. Co więcej, TSDS jest elastyczne i może być stosowane w różnych przestrzeniach metrycznych, które wspierają efektywne wyszukiwanie najbliższych sąsiadów, co czyni je wszechstronnym rozwiązaniem dla różnorodnych zadań i architektur modeli.
Znaczenie i wpływ TSDS
TSDS to znaczący krok naprzód w porównaniu z tradycyjnymi metodami selekcji danych, szczególnie w przypadku pracy z dużymi zbiorami danych. W testach obejmujących dostrajanie modeli językowych oraz pretrenowanie w specyficznych domenach TSDS wykazało lepsze wyniki niż metody bazowe. Na przykład przy współczynniku selekcji wynoszącym 1% TSDS poprawiło średni wynik F1 o 1,5 punktu w porównaniu z metodami bazowymi podczas dostrajania dużych modeli językowych. Dodatkowo TSDS okazało się odporne na obecność zduplikowanych danych i utrzymało wysoką wydajność, nawet gdy w puli kandydatów znajdowało się do 1000 duplikatów.
Efektywność TSDS to kolejna istotna zaleta. W jednym z eksperymentów TSDS przetworzyło zbiór 150 milionów przykładów w ciągu 28 godzin, a selekcja danych dla konkretnego zadania trwała mniej niż godzinę. Tak wysoka efektywność sprawia, że TSDS jest idealnym rozwiązaniem dla zastosowań w rzeczywistych warunkach, gdzie czas i zasoby obliczeniowe są ograniczone.
Podsumowanie
TSDS to przełomowe rozwiązanie w dziedzinie dostrajania modeli do specyficznych zadań. Dzięki podejściu opartemu na optymalizacji, które łączy dopasowanie rozkładu danych z ich różnorodnością, TSDS gwarantuje, że wybrane dane są zarówno trafne, jak i reprezentatywne dla zadania docelowego. W rezultacie możliwe jest osiągnięcie lepszej wydajności modeli, zmniejszenie ryzyka nadmiernego dopasowania oraz bardziej efektywne wykorzystanie zasobów obliczeniowych. W miarę jak modele uczenia maszynowego stają się coraz bardziej zaawansowane, rozwiązania takie jak TSDS będą odgrywać kluczową rolę w zwiększaniu skuteczności i dostępności fine-tuningu w różnych zastosowaniach. Dalsze badania mogą skupić się na ulepszaniu algorytmów transportu optymalnego lub doskonaleniu wyboru reprezentatywnych przykładów, aby jeszcze bardziej zminimalizować potencjalne uprzedzenia w danych.