„Neural Magic prezentuje LLM Compressor: Nowa biblioteka do przyspieszania działania modeli językowych dzięki kompresji i technologii vLLM”
Nowe narzędzie do optymalizacji dużych modeli językowych
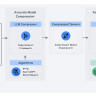
Neural Magic zaprezentowało LLM Compressor, narzędzie nowej generacji dedykowane optymalizacji dużych modeli językowych (LLM). Dzięki zaawansowanej technologii kompresji modelu, LLM Compressor znacząco przyspiesza proces inferencji (wnioskowania), co stanowi kluczowy krok na drodze do tworzenia wysokowydajnych, otwartych rozwiązań dla społeczności zajmującej się uczeniem głębokim. Narzędzie to integruje się szczególnie dobrze z frameworkiem vLLM, co dodatkowo podkreśla jego potencjał.
—
Ujednolicenie narzędzi do kompresji modeli
Dotychczasowe podejścia do kompresji modeli wiązały się z koniecznością korzystania z wielu rozproszonych narzędzi, takich jak AutoGPTQ, AutoAWQ czy AutoFP8. Każde z tych narzędzi wymagało od użytkowników tworzenia dedykowanych bibliotek, co utrudniało proces optymalizacji. LLM Compressor eliminuje te trudności, łącząc najnowocześniejsze algorytmy kompresji, takie jak GPTQ, SmoothQuant i SparseGPT, w jedną bibliotekę. Dzięki temu użytkownicy mogą tworzyć zoptymalizowane modele o niższej latencji inferencji, które jednocześnie zachowują wysoką dokładność. Jest to szczególnie istotne w środowiskach produkcyjnych, gdzie precyzja ma kluczowe znaczenie.
—
Innowacje w kwantyzacji i wydajności
Jednym z najważniejszych ulepszeń technicznych oferowanych przez LLM Compressor jest wsparcie dla kwantyzacji wag i aktywacji. Szczególnie istotna jest tutaj kwantyzacja aktywacji, która umożliwia wykorzystanie rdzeni tensorowych INT8 i FP8, zoptymalizowanych pod kątem architektur GPU nowej generacji, takich jak Ada Lovelace i Hopper od NVIDIA. Dzięki temu narzędzie pozwala na znaczne zwiększenie wydajności obliczeniowej, zmniejszając wąskie gardła związane z dużym zapotrzebowaniem na moc obliczeniową.
Przykładowo, w przypadku modelu Llama 3.1 70B, zastosowanie LLM Compressor pozwala na osiągnięcie wydajności inferencji zbliżonej do wersji niekwantyzowanej działającej na czterech GPU, przy użyciu jedynie dwóch GPU. Oznacza to nawet dwukrotny wzrost wydajności w zadaniach inferencyjnych pod dużym obciążeniem serwera.
—
Redukcja rozmiaru modelu dzięki rzadkości strukturalnej
LLM Compressor wspiera również zaawansowaną rzadkość strukturalną (structured sparsity), w tym przycinanie wag 2:4 przy użyciu algorytmu SparseGPT. Proces ten polega na usuwaniu zbędnych parametrów modelu, co zmniejsza jego rozmiar o 50%, przy minimalnej utracie dokładności. Połączenie kwantyzacji i przycinania wag pozwala nie tylko przyspieszyć inferencję, ale także zredukować zapotrzebowanie na pamięć, co otwiera możliwość wdrażania dużych modeli językowych na urządzeniach o ograniczonych zasobach sprzętowych.
—
Łatwość integracji i elastyczność konfiguracji
LLM Compressor został zaprojektowany tak, aby łatwo integrować się z otwartymi ekosystemami, w szczególności z popularnym repozytorium Hugging Face. Dzięki temu użytkownicy mogą bezproblemowo ładować i uruchamiać skompresowane modele w środowisku vLLM. Narzędzie obsługuje różnorodne schematy kwantyzacji, umożliwiając precyzyjną kontrolę nad procesem, np. kwantyzację na poziomie tensorów lub kanałów dla wag oraz tensorów lub tokenów dla aktywacji. Tak wysoka elastyczność pozwala dostosować model do różnych wymagań dotyczących wydajności i dokładności w zależności od scenariusza wdrożeniowego.
—
Plany na przyszłość
LLM Compressor jest narzędziem wszechstronnym, zaprojektowanym z myślą o wspieraniu szerokiej gamy architektur modeli. Twórcy narzędzia przygotowali ambitną mapę rozwoju, która obejmuje rozszerzenie wsparcia na modele MoE (Mixture of Experts), modele łączące tekst i obraz (vision-language models) oraz platformy sprzętowe inne niż NVIDIA. W planach są także zaawansowane techniki kwantyzacji, takie jak AWQ, oraz narzędzia do tworzenia nienormatywnych schematów kwantyzacji, które jeszcze bardziej zwiększą efektywność modeli.
—
Znaczenie dla przyszłości AI
LLM Compressor to niezwykle ważne narzędzie dla badaczy i praktyków, którzy chcą zoptymalizować modele językowe do zastosowań produkcyjnych. Dzięki otwartemu kodowi źródłowemu oraz zaawansowanym funkcjom, narzędzie to ułatwia proces kompresji modeli i pozwala na osiągnięcie znaczących popraw w wydajności bez utraty jakości. W miarę jak sztuczna inteligencja będzie się rozwijać, tego typu rozwiązania odegrają kluczową rolę w efektywnym wdrażaniu dużych modeli na różnorodnych platformach sprzętowych, czyniąc je bardziej dostępnymi i praktycznymi w wielu dziedzinach.





